项目中有时候我们会遇到 excel 导入的需求, excle 文件的每一行记录对应的可能都是数据库中的一条记录,一个 excel 中可能有很多行,所以导入一个 excel 就意味着 excel 里面有多少行,我们就要插入多少条记录。如果我们采用一条一条记录插入的方式,毫无疑问,这可能要执行很久。
如果是采用同步的方式的话,页面就会需要等好长一段时间才能有响应。就算采用异步的方式,先给前端一个响应,后台异步执行插入操作,用户也会需要等好长一段时间才能看到刚才 excel 导入的数据。
这时候批量插入的方式就显得很有必要了。这里我们采用 JdbcTemplate 来实现批量插入。
这里再次以活动统计表 activity_stats 来举例,比如需求就是要导入一份活动统计的 excel 数据,这里为了简单起见,就通过 for 循环来模拟构造一份 excel 数据。
这里我两种方式都实现了,一种是通过 for 循环一个一个保存的,另一种则是批量插入。先声明我测试使用的 mysql 驱动版本是:
1 2 3 4 5 <dependency > <groupId > mysql</groupId > <artifactId > mysql-connector-java</artifactId > <version > 8.0.19</version > </dependency >
spring jdbc 依赖版本是:
1 2 3 4 5 <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-jdbc</artifactId > <version > 2.2.6.RELEASE</version > </dependency >
首先我们看 for 循环的方式,代码很简单,我就直接贴出来了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public void insertStats (List<ActivityStat> activityStatList) if (CollectionUtils.isEmpty(activityStatList)){ return ; } String sql = "insert into activity_stats(activity_id, times_viewed, works_count, user_count) values(?, ?, ?, ?)" ; long start = System.currentTimeMillis(); activityStatList.forEach(item -> { this .jdbcTemplate.update(sql, preparedStatement -> { preparedStatement.setLong(1 , item.getActivityId()); preparedStatement.setLong(2 , item.getTimesViewed()); preparedStatement.setLong(3 , item.getWorksCount()); preparedStatement.setLong(4 , item.getUserCount()); }); }); log.info("insert state cost {} s" , (System.currentTimeMillis() - start) / 1000 ); }
下面则是批量的方式:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public void batchInsertStats (List<ActivityStat> activityStatList) if (CollectionUtils.isEmpty(activityStatList)){ return ; } String sql = "insert into activity_stats(activity_id, times_viewed, works_count, user_count) values(?, ?, ?, ?)" ; long start = System.currentTimeMillis(); this .jdbcTemplate.batchUpdate(sql, new BatchPreparedStatementSetter() { @Override public void setValues (PreparedStatement preparedStatement, int i) throws SQLException ActivityStat data = activityStatList.get(i); preparedStatement.setLong(1 , data.getActivityId()); preparedStatement.setLong(2 , data.getTimesViewed()); preparedStatement.setLong(3 , data.getWorksCount()); preparedStatement.setLong(4 , data.getUserCount()); } @Override public int getBatchSize () return activityStatList.size(); } }); log.info("batch insert state cost {} s" , (System.currentTimeMillis() - start) / 1000 ); }
代码实现写好了,接下来我们来测试下看看效果
1 2 3 4 5 6 7 8 9 10 11 @Test public void testInsertStats () List<ActivityStat> activityStatList = mockStatsData(); this .activityStatService.insertStats(activityStatList); } @Test public void testBatchInsertStats () List<ActivityStat> activityStatList = mockStatsData(); this .activityStatService.batchInsertStats(activityStatList); }
其中 mockStatsData() 方法是一个 for 循环构建了 10000 个 ActivityStat,返回 activityStatList:
1 2 3 4 5 6 7 8 9 10 11 12 private List<ActivityStat> mockStatsData () List<ActivityStat> activityStatList = new ArrayList<>(10000 ); for (int i = 0 ; i < 10000 ; i++){ ActivityStat activityStat = new ActivityStat(); activityStat.setActivityId((long )i) .setTimesViewed((long )(i + 100 )) .setWorksCount((long ) i + 50 ) .setUserCount((long ) i + 10 ); activityStatList.add(activityStat); } return activityStatList; }
运行测试的结果是下面这样的:
往数据库中插入 10000 条记录,采用 for 循环的方式和采用批量的方式插入竟然时间量级是一样的,是不是有点懵,说实话刚开始我也有点懵,就觉得不应该啊,如果这样的话那还要 batchUpdate 方法有什么意义呢。
懵归懵,但还是要找出其中的原因来,正常来说肯定不会是这种结果,应该是哪个环节没弄好,从我们写的代码来看应该是没有问题的,那就通过 debug 的方式看看 batchUpdate 方法里面到底是怎么执行的。这里建议如果要 debug 的源码是稍微比较复杂的,建议不要直接看 class 文件,calss 文件毕竟是编译之后的,代码看起来不是那么的直观,可以在打开 class 文件之后点击右上角提示的下载源码按钮。
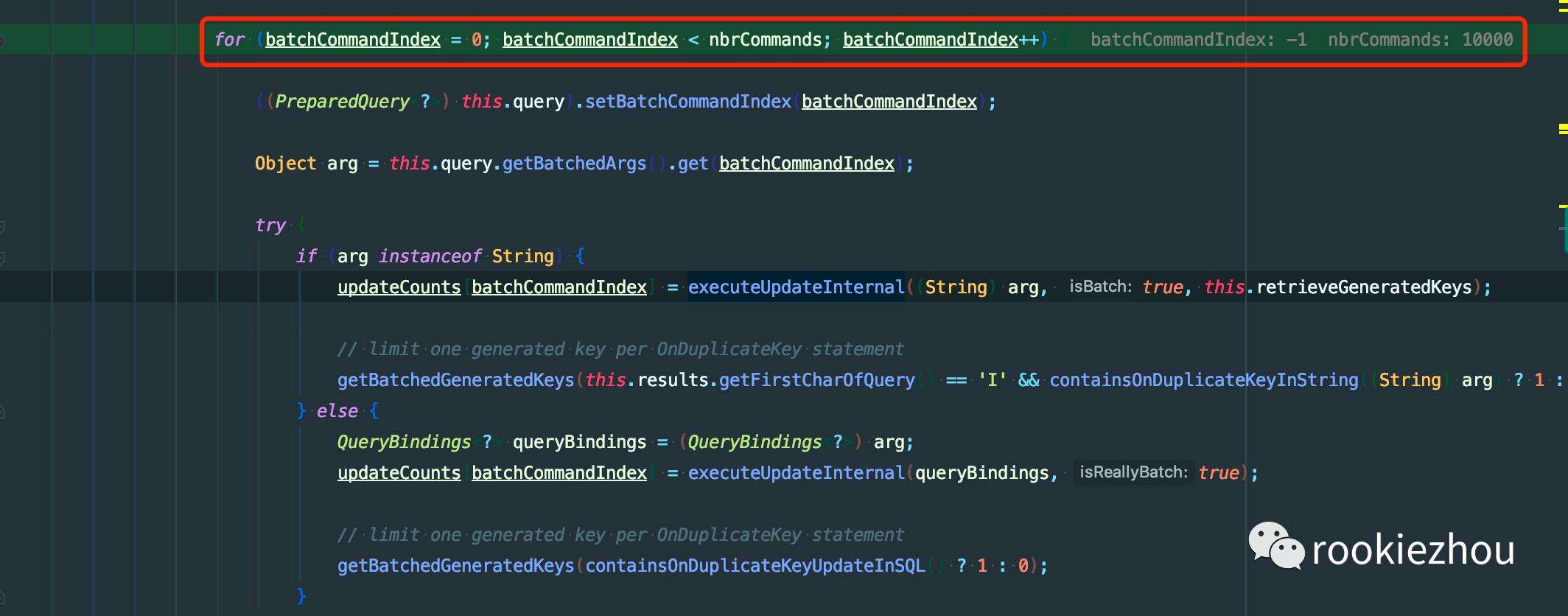
通过 debug 的方式我在 ClientPreparedStatement 类中找到下面这样一段代码:
这里有个判断 !this.batchHasPlainStatements && this.rewriteBatchedStatements.getValue()
当上面这两个条件只要有一个不满足,就会执行最下面的 executeBatchSerially 方法,而在这个方法的内部可以看到有一个 for 循环,然后在 for 循环里面一个一个执行 SQL。
看到这里再仔细看上面两个条件,对于 !this.batchHasPlainStatements 是类的一个属性,默认值是 false:
1 2 3 4 5 6 7 protected boolean batchHasPlainStatements = false ;
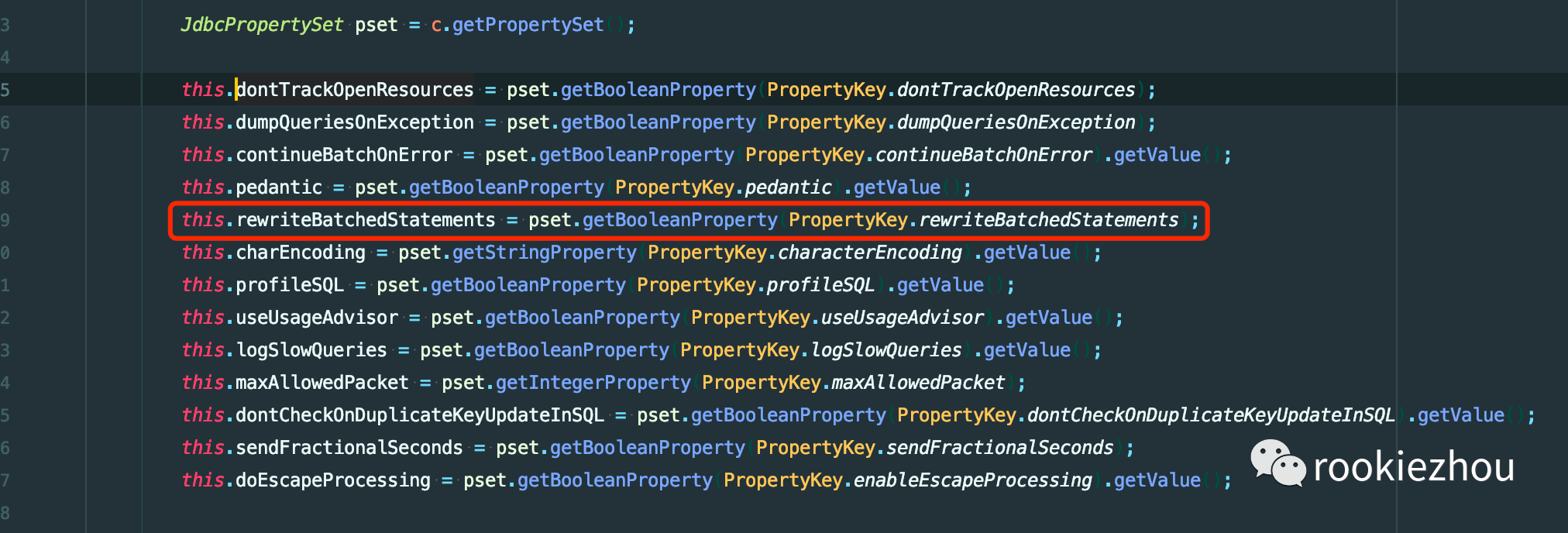
只有在 addBatch 方法中才会置为 true,所以第一个条件满足的。再看第二个条件 thi.rewriteBatchedStatements,是父类的一个属性:
1 protected RuntimeProperty<Boolean> rewriteBatchedStatements;
到这里我们应该知道为什么批量执行的方式和 for 循环一个一个插入时间量级是一样的了,是由于我们的少了rewriteBatchedStatements=true 的配置,导致 batchUpdate 代码内部其实还是通过 for 循环的方式来执行的,所以量级才会是一样的,接下来我们加上这项配置再执行就可以看到速度明显上来了,下面是加上改配置执行之后的结果:
插入 10000 条记录用时才 2s,而加上配置之前是 30s。其实 rewriteBatchedStatements=true 配置对于批量的 insert 语句来说,是实现了下面的效果:
1 2 3 4 5 insert into activity_stats(activity_id, times_viewed, works_count, user_count) values (?, ?, ?, ?);insert into activity_stats(activity_id, times_viewed, works_count, user_count) values (?, ?, ?, ?);insert into activity_stats(activity_id, times_viewed, works_count, user_count) values (?, ?, ?, ?)insert into activity_stats(activity_id, times_viewed, works_count, user_count) values (?, ?, ?, ?),(?, ?, ?, ?),(?, ?, ?, ?);
也就是是否将多条重写成一条,然后在发给 MySQL 执行,这样不用一条一条发过去执行,大大提高了执行效率。
好了,上面整体就是 JdbcTemplate 批量插入的实现,记得千万不要忘了加上 rewriteBatchedStatements=true 的配置,不然可能你写完了以为已经实现了批量插入,但结果根本没有达到批量执行的效果。